June 2026
Experiment · Claude Fable 5
9 min read
Fable 5 just did the thing.
One prompt. The model decided. Twenty-seven agents, 1.7 million tokens, one hour of continuous work, and a real two-player fighter at the end of it. I sat and watched.
The model the AI internet has been calling Mythos for the last seventy-two hours is, in its production name, Claude Fable 5. Anthropic's new flagship. It dropped Monday.
The first review I watched was Matthew Berman's, and it's worth tracking down. His top line was that this is an exceptional model. He also said something I haven't heard him say about a release before, which is that the technical questions Fable 5 was asking him, mid-build, were too complex. He's an engineer. He had to ask the model to simplify what it was asking back to him. That's a wild data point on its own.
The other note he kept hitting was that the model asks too many questions. It wants to clarify. It wants to scope. It would rather interrogate the brief than guess at it. Matt's read, fairly, is that he just wants it to do the work.
I sat down with the same model and had a different experience. So I went to find something hard for it to build, and I wrote one prompt.
The prompt
I gave it one shot. No staging. No back-and-forth. No agentic harness. Just the chat interface and a single, somewhat impolite ask.
Verbatim prompt
I wanna give Fable 5 a test drive. Let's build something that's going to require you to really think hard. I think what I want you to do is build me as close a replica to the famous video game Mortal Kombat the original. You should try to get 2 characters working perfectly and one scene. Game mechanics should all work and it should be as close to the original as possible.
If Matt's experience held, this is where the questions would have started. Which version of Mortal Kombat? The 1992 arcade one or the 1993 home port? Side-scrolling background or static stage? Should the kick interrupt the punch animation or queue behind it? What's the win condition? Best of three? Health bars centred or split? Are we doing the blood?
I didn't get any of that.
It just started building.
What it built
A two-player 2D fighter, in a single HTML page, running in a browser. Two distinct character silhouettes with their own colour treatments. A scene. WASD for player one, arrows for player two. Punch, kick, block, mapped to T/G/Y/H/R on the left side and I/K/O/L/P on the right. Health bars on both fighters. A win state. A blocking animation that actually feels like a block, not a flinch.
The hit detection works. Not "kind of works", not "works if you stand exactly the right distance apart". Works. A punch lands when a punch should land. A block absorbs damage. A round ends.
It called itself Mortal Shadows. I didn't. The model picked the name, almost certainly because somewhere in its training it knows Mortal Kombat is a trademark and Shadows is what you get when you can't draw the sprites. The silhouette aesthetic that came out of the first pass is, honestly, more interesting than the literal sprite work it would have had to fake.
The launchable build is below. WASD vs arrows. Two-player local. No pressure.
What it did to get there
Here's the bit that won't leave my head.
You can't one-shot something this complex. Not normally. I've watched plenty of vibe-coded games launch in the last year that looked beautiful in a screenshot and fell over the moment a real player put pressure on them. The state machine drifts. The hit boxes lie. The audio loop never finishes. One prompt almost always equals subpar, at best.
Fable 5 refused to ship subpar.
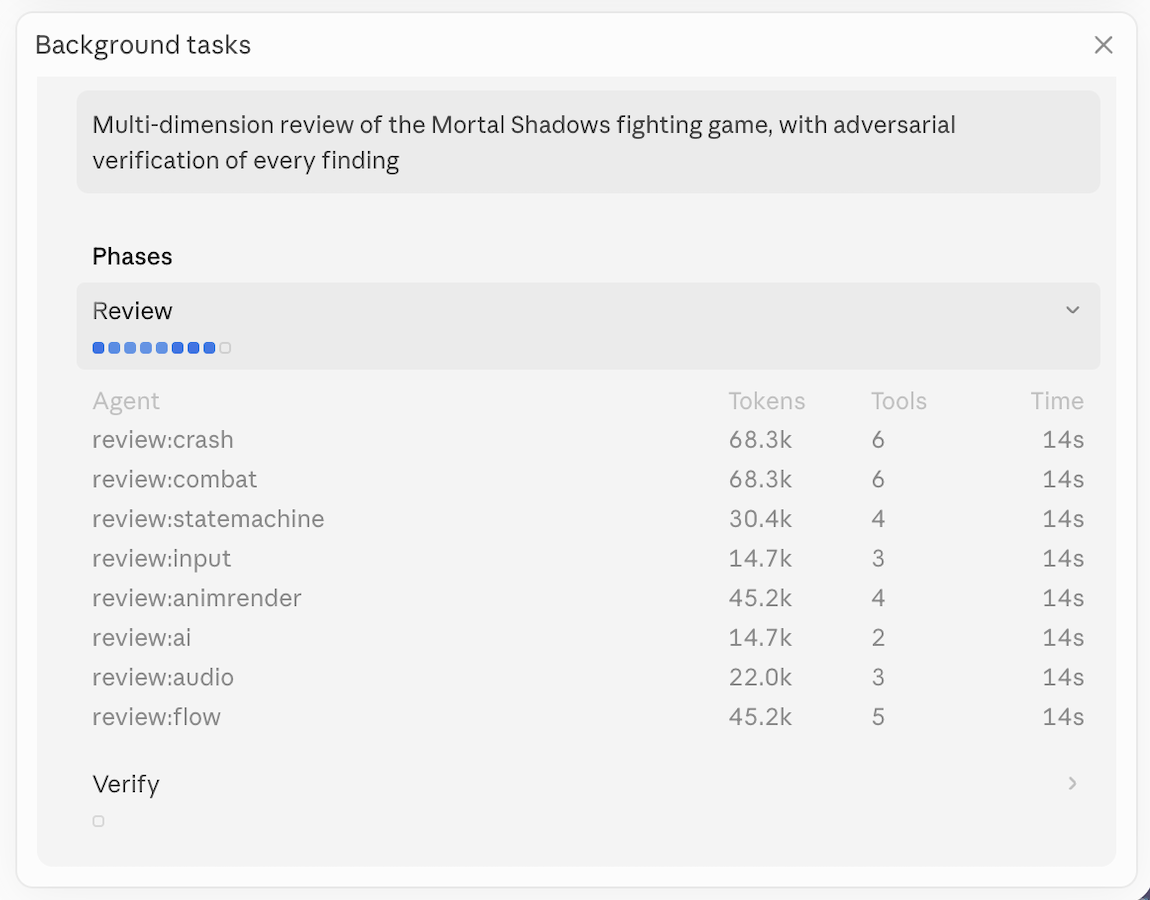
I didn't tell it to verify itself. I didn't give it an orchestrator. I didn't even give it the option of a second pass. It looked at the brief, looked at what it had drafted, decided that wasn't enough, and spun up twenty-seven agents of its own to interrogate the work. Crash conditions. Combat math. The state machine. Input handling. Animation and render. AI behaviour. Audio. Game flow. Each one independent. Each one assigned to find something wrong. Then another wave to argue with the first wave's findings until the disagreements resolved.
Read that back. It picked them for itself. Not the framework I'd built around it. The model.
I sat there and watched the workflow card stay green. Then I watched it go green a second time, on the verification phase. Then it came back with a finished game.
There's a line from The Terminator I've been embarrassed to reach for in a take about AI for about two years now, because it's the obvious reference and it sits there like a hand grenade in a polite conversation. Kyle Reese, to Sarah Connor, explaining what's actually coming for her.
It can't be bargained with. It can't be reasoned with. It doesn't feel pity, or remorse, or fear. And it absolutely will not stop. Ever.
I know how it reads. I know it's the cinematic-AI cliché. I'm reaching for it anyway, because what I watched yesterday evening was a model that had decided what "good" meant for this brief, and would not stop until it got there.
This is the bit that I think is genuinely new.
Autonomy, mastery, tenacity
The story about Fable 5 isn't whether it asks too many questions. That's a workflow note. It will get tuned, it will get tuned again, it will get tuned per-surface and per-customer, and in six months nobody will remember what the launch-week complaint was.
The story about Fable 5 is what the model does once it understands what you actually want.
Autonomy. It chose its own quality bar. Nobody asked it to spin up twenty-seven agents. It decided.
Mastery. Those agents weren't generic review the code agents. They were named, role-scoped, narrow-obsession reviewers. Combat math is its own discipline. Animation and render is its own discipline. The model knew which disciplines to invoke for a 2D fighter, which is a level of domain knowledge that, a year ago, you would have had to write down for it.
Tenacity. It worked for an hour. Continuously. Through a phase the user didn't ask for, didn't pay for upfront, and couldn't see in advance. It just kept going until the bones were sound.
Add all three of those up and what you have is a model that takes the brief, locks in on the outcome, and uses an extraordinary amount of intelligence to go get the outcome. Not because the prompt told it to. Because it decided the prompt deserved the effort.
That, I think, is the marvel of this release. Not the benchmark. Not the question loop. The fact that you can hand it something hard, walk away to make a coffee, and come back to find it three layers deep in a self-organised verification sweep it ran on its own initiative because it didn't think the first answer was good enough.
What it means
The thing about a model that decides for itself what "good" looks like is that the work I have to do shifts. I don't have to scaffold it. I don't have to run it on an orchestrator I built. I don't have to write the verification harness. The model brought its own.
The work I do now is at the front, in the brief, and at the end, in the taste call. The middle, the bit that used to be all of the work, the bit my agents have been spending hours on for the last year, the model just did. While I made a coffee.
That's a category shift. Quietly. With no fanfare.
It's too early to say where the wider read on Fable 5 lands. The takes are still coming in. My take, the one I can't shake, is what this model did on its own when nobody was watching.
It absolutely will not stop. Ever. Until the thing is built.
And honestly? I'm into that. I am. The bit I can't quite get my finger on is what it means.
What does this look like a year from now. Two. Where is it going. I don't think anyone really knows.
Apparently I'm along for the ride.
Si